import pandas as pd
Y_df = pd.read_parquet('https://datasets-nixtla.s3.amazonaws.com/m4-hourly.parquet')Nixtla - Neural Advanced Forecast
Model training, evaluation and selection for multiple time series
WarningPrerequesites
This Guide assumes basic familiarity with NeuralForecast. For a minimal example visit the Quick Start
Follow this article for a step to step guide on building a production-ready forecasting pipeline for multiple time series.
During this guide you will gain familiary with the core NueralForecastclass and some relevant methods like NeuralForecast.fit, NeuralForecast.predict, and StatsForecast.cross_validation.
We will use a classical benchmarking dataset from the M4 competition. The dataset includes time series from different domains like finance, economy and sales. In this example, we will use a subset of the Hourly dataset.
We will model each time series globally Therefore, you will train a set of models for the whole dataset, and then select the best model for each individual time series. NeuralForecast focuses on speed, simplicity, and scalability, which makes it ideal for this task.
Outline:
- Install packages.
- Read the data.
- Explore the data.
- Train many models globally for the entire dataset.
- Evaluate the model’s performance using cross-validation.
- Select the best model for every unique time series.
TipNot Covered in this guide
- Using external regressors or exogenous variables
- Follow this tutorial to include exogenous variables like weather or holidays or static variables like category or family.
- Probabilistic forecasting
- Follow this tutorial to generate probabilistic forecasts
- Transfer Learning
- Train a model and use it to forecast on different data using this tutorial
Tip
You can use Colab to run this Notebook interactively ![]()
Warning
To reduce the computation time, it is recommended to use GPU. Using Colab, do not forget to activate it. Just go to Runtime>Change runtime type and select GPU as hardware accelerator.
1. Install libraries
We assume you have NeuralForecast already installed. Check this guide for instructions on how to install NeuralForecast.
Additionally, we will install s3fs to read from the S3 Filesystem of AWS, statsforecast for plotting, and datasetsforecast for common error metrics like MAE or MASE.
Install the necessary packages using pip install statsforecast s3fs datasetsforecast ``
%%capture ! pip install statsforecast s3fs datasetsforecast
%%capture ! pip install git+https://github.com/Nixtla/neuralforecast.git@main
2. Read the data
We will use pandas to read the M4 Hourly data set stored in a parquet file for efficiency. You can use ordinary pandas operations to read your data in other formats likes .csv.
The input to NeuralForecast is always a data frame in long format with three columns: unique_id, ds and y:
The
unique_id(string, int or category) represents an identifier for the series.The
ds(datestamp or int) column should be either an integer indexing time or a datestampe ideally like YYYY-MM-DD for a date or YYYY-MM-DD HH:MM:SS for a timestamp.The
y(numeric) represents the measurement we wish to forecast. We will rename the
This data set already satisfies the requirement.
Depending on your internet connection, this step should take around 10 seconds.
Y_df.head(), len(Y_df.unique_id.unique())( unique_id ds y
0 H1 1 605.0
1 H1 2 586.0
2 H1 3 586.0
3 H1 4 559.0
4 H1 5 511.0,
414)This dataset contains 414 unique series with 900 observations on average. For this example and reproducibility’s sake, we will select only 10 unique IDs. Depending on your processing infrastructure feel free to select more or less series.
Note
Processing time is dependent on the available computing resources. Running this example with the complete dataset takes around 10 minutes in a c5d.24xlarge (96 cores) instance from AWS.
uids = Y_df['unique_id'].unique()[:10] # Select 10 ids to make the example faster
Y_df = Y_df.query('unique_id in @uids').reset_index(drop=True)3. Explore Data with the plot method of StatsForecast
Plot some series using the plot method from the StatsForecast class. This method prints 8 random series from the dataset and is useful for basic EDA.
Note
The StatsForecast.plot method uses Plotly as a defaul engine. You can change to MatPlotLib by setting engine="matplotlib".
from statsforecast import StatsForecast
StatsForecast.plot(Y_df, engine='matplotlib')/home/ben/mambaforge/envs/cfast/lib/python3.11/site-packages/statsforecast/core.py:25: TqdmExperimentalWarning: Using `tqdm.autonotebook.tqdm` in notebook mode. Use `tqdm.tqdm` instead to force console mode (e.g. in jupyter console)
from tqdm.autonotebook import tqdm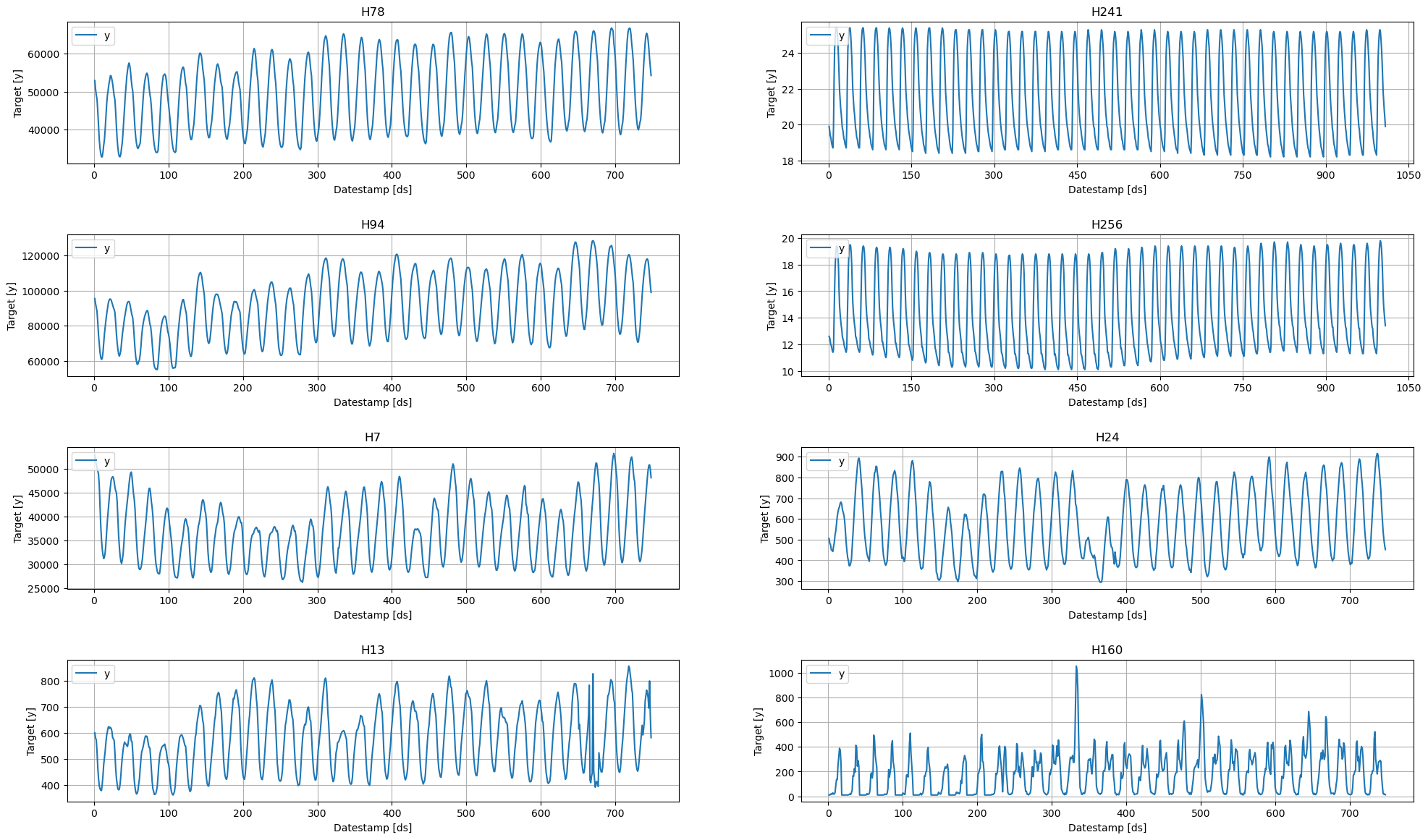
4. Train multiple models for many series
NeuralForecast can train many models on many time series globally and efficiently.
from ray import tune
from neuralforecast import NeuralForecast
from neuralforecast.auto import AutoNHITS, AutoLSTM
from neuralforecast.losses.pytorch import MQLossEach Auto model contains a default search space that was extensively tested on multiple large-scale datasets. Additionally, users can define specific search spaces tailored for particular datasets and tasks.
First, we create a custom search space for the AutoNHITS and AutoLSTM models. Search spaces are specified with dictionaries, where keys corresponds to the model’s hyperparameter and the value is a Tune function to specify how the hyperparameter will be sampled. For example, use randint to sample integers uniformly, and choice to sample values of a list.
config_nhits = {
"input_size": tune.choice([48, 48*2, 48*3]), # Length of input window
"start_padding_enabled": True,
"n_blocks": 5*[1], # Length of input window
"mlp_units": 5 * [[64, 64]], # Length of input window
"n_pool_kernel_size": tune.choice([5*[1], 5*[2], 5*[4],
[8, 4, 2, 1, 1]]), # MaxPooling Kernel size
"n_freq_downsample": tune.choice([[8, 4, 2, 1, 1],
[1, 1, 1, 1, 1]]), # Interpolation expressivity ratios
"learning_rate": tune.loguniform(1e-4, 1e-2), # Initial Learning rate
"scaler_type": tune.choice([None]), # Scaler type
"max_steps": tune.choice([1000]), # Max number of training iterations
"batch_size": tune.choice([1, 4, 10]), # Number of series in batch
"windows_batch_size": tune.choice([128, 256, 512]), # Number of windows in batch
"random_seed": tune.randint(1, 20), # Random seed
}
config_lstm = {
"input_size": tune.choice([48, 48*2, 48*3]), # Length of input window
"encoder_hidden_size": tune.choice([64, 128]), # Hidden size of LSTM cells
"encoder_n_layers": tune.choice([2,4]), # Number of layers in LSTM
"learning_rate": tune.loguniform(1e-4, 1e-2), # Initial Learning rate
"scaler_type": tune.choice(['robust']), # Scaler type
"max_steps": tune.choice([500, 1000]), # Max number of training iterations
"batch_size": tune.choice([1, 4]), # Number of series in batch
"random_seed": tune.randint(1, 20), # Random seed
}To instantiate an Auto model you need to define:
h: forecasting horizon.loss: training and validation loss fromneuralforecast.losses.pytorch.config: hyperparameter search space. IfNone, theAutoclass will use a pre-defined suggested hyperparameter space.search_alg: search algorithm (fromtune.search), default is random search. Refer to https://docs.ray.io/en/latest/tune/api_docs/suggestion.html for more information on the different search algorithm options.num_samples: number of configurations explored.
In this example we set horizon h as 48, use the MQLoss distribution loss for training and validation, and use the default search algorithm.
nf = NeuralForecast(
models=[
AutoNHITS(h=48, config=config_nhits, loss=MQLoss(), num_samples=5),
AutoLSTM(h=48, config=config_lstm, loss=MQLoss(), num_samples=2),
],
freq='H'
)
Tip
The number of samples, num_samples, is a crucial parameter! Larger values will usually produce better results as we explore more configurations in the search space, but it will increase training times. Larger search spaces will usually require more samples. As a general rule, we recommend setting num_samples higher than 20.
Next, we use the Neuralforecast class to train the Auto model. In this step, Auto models will automatically perform hyperparameter tuning training multiple models with different hyperparameters, producing the forecasts on the validation set, and evaluating them. The best configuration is selected based on the error on a validation set. Only the best model is stored and used during inference.
nf.fit(df=Y_df)2023-12-08 16:03:28,784 INFO worker.py:1673 -- Started a local Ray instance.
2023-12-08 16:03:31,402 INFO tune.py:220 -- Initializing Ray automatically. For cluster usage or custom Ray initialization, call `ray.init(...)` before `Tuner(...)`.
2023-12-08 16:03:31,405 INFO tune.py:586 -- [output] This uses the legacy output and progress reporter, as Jupyter notebooks are not supported by the new engine, yet. For more information, please see https://github.com/ray-project/ray/issues/36949
2023-12-08 16:04:31,718 WARNING insufficient_resources_manager.py:163 -- Ignore this message if the cluster is autoscaling. No trial is running and no new trial has been started within the last 60 seconds. This could be due to the cluster not having enough resources available. You asked for 0 CPUs and 1.0 GPUs per trial, but the cluster only has 12.0 CPUs and 0 GPUs available. Stop the tuning and adjust the required resources (e.g. via the `ScalingConfig` or `resources_per_trial`, or `num_workers` for rllib), or add more resources to your cluster.
2023-12-08 16:05:31,748 WARNING insufficient_resources_manager.py:163 -- Ignore this message if the cluster is autoscaling. No trial is running and no new trial has been started within the last 60 seconds. This could be due to the cluster not having enough resources available. You asked for 0 CPUs and 1.0 GPUs per trial, but the cluster only has 12.0 CPUs and 0 GPUs available. Stop the tuning and adjust the required resources (e.g. via the `ScalingConfig` or `resources_per_trial`, or `num_workers` for rllib), or add more resources to your cluster.
2023-12-08 16:05:36,474 WARNING tune.py:186 -- Stop signal received (e.g. via SIGINT/Ctrl+C), ending Ray Tune run. This will try to checkpoint the experiment state one last time. Press CTRL+C (or send SIGINT/SIGKILL/SIGTERM) to skip.
2023-12-08 16:05:36,490 WARNING tune.py:1062 -- Experiment has been interrupted, but the most recent state was saved.
Resume experiment with: Tuner.restore(path="/home/ben/ray_results/_train_tune_2023-12-08_16-03-25", trainable=...)
2023-12-08 16:05:36,495 WARNING experiment_analysis.py:185 -- Failed to fetch metrics for 5 trial(s):
- _train_tune_7b276_00000: FileNotFoundError('Could not fetch metrics for _train_tune_7b276_00000: both result.json and progress.csv were not found at /home/ben/ray_results/_train_tune_2023-12-08_16-03-25/_train_tune_7b276_00000_0_batch_size=10,input_size=96,learning_rate=0.0002,max_steps=1000,n_freq_downsample=1_1_1_1_1,n_pool_kerne_2023-12-08_16-03-31')
- _train_tune_7b276_00001: FileNotFoundError('Could not fetch metrics for _train_tune_7b276_00001: both result.json and progress.csv were not found at /home/ben/ray_results/_train_tune_2023-12-08_16-03-25/_train_tune_7b276_00001_1_batch_size=4,input_size=48,learning_rate=0.0045,max_steps=1000,n_freq_downsample=1_1_1_1_1,n_pool_kernel_2023-12-08_16-03-31')
- _train_tune_7b276_00002: FileNotFoundError('Could not fetch metrics for _train_tune_7b276_00002: both result.json and progress.csv were not found at /home/ben/ray_results/_train_tune_2023-12-08_16-03-25/_train_tune_7b276_00002_2_batch_size=1,input_size=96,learning_rate=0.0032,max_steps=1000,n_freq_downsample=8_4_2_1_1,n_pool_kernel_2023-12-08_16-03-31')
- _train_tune_7b276_00003: FileNotFoundError('Could not fetch metrics for _train_tune_7b276_00003: both result.json and progress.csv were not found at /home/ben/ray_results/_train_tune_2023-12-08_16-03-25/_train_tune_7b276_00003_3_batch_size=10,input_size=144,learning_rate=0.0004,max_steps=1000,n_freq_downsample=8_4_2_1_1,n_pool_kern_2023-12-08_16-03-31')
- _train_tune_7b276_00004: FileNotFoundError('Could not fetch metrics for _train_tune_7b276_00004: both result.json and progress.csv were not found at /home/ben/ray_results/_train_tune_2023-12-08_16-03-25/_train_tune_7b276_00004_4_batch_size=4,input_size=144,learning_rate=0.0003,max_steps=1000,n_freq_downsample=8_4_2_1_1,n_pool_kerne_2023-12-08_16-03-31')
2023-12-08 16:05:36,495 WARNING experiment_analysis.py:575 -- Could not find best trial. Did you pass the correct `metric` parameter?--------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) Cell In[14], line 1 ----> 1 nf.fit(df=Y_df) File ~/mambaforge/envs/cfast/lib/python3.11/site-packages/neuralforecast/core.py:274, in NeuralForecast.fit(self, df, static_df, val_size, sort_df, use_init_models, verbose) 271 print("WARNING: Deleting previously fitted models.") 273 for model in self.models: --> 274 model.fit(self.dataset, val_size=val_size) 276 self._fitted = True File ~/mambaforge/envs/cfast/lib/python3.11/site-packages/neuralforecast/common/_base_auto.py:373, in BaseAuto.fit(self, dataset, val_size, test_size, random_seed) 360 if self.backend == "ray": 361 results = self._tune_model( 362 cls_model=self.cls_model, 363 dataset=dataset, (...) 371 config=self.config, 372 ) --> 373 best_config = results.get_best_result().config 374 else: 375 results = self._optuna_tune_model( 376 cls_model=self.cls_model, 377 dataset=dataset, (...) 383 config=self.config, 384 ) File ~/mambaforge/envs/cfast/lib/python3.11/site-packages/ray/tune/result_grid.py:162, in ResultGrid.get_best_result(self, metric, mode, scope, filter_nan_and_inf) 151 error_msg = ( 152 "No best trial found for the given metric: " 153 f"{metric or self._experiment_analysis.default_metric}. " 154 "This means that no trial has reported this metric" 155 ) 156 error_msg += ( 157 ", or all values reported for this metric are NaN. To not ignore NaN " 158 "values, you can set the `filter_nan_and_inf` arg to False." 159 if filter_nan_and_inf 160 else "." 161 ) --> 162 raise RuntimeError(error_msg) 164 return self._trial_to_result(best_trial) RuntimeError: No best trial found for the given metric: loss. This means that no trial has reported this metric, or all values reported for this metric are NaN. To not ignore NaN values, you can set the `filter_nan_and_inf` arg to False.
(raylet) [2023-12-08 16:11:28,719 E 602035 602035] (raylet) node_manager.cc:3035: 5 Workers (tasks / actors) killed due to memory pressure (OOM), 0 Workers crashed due to other reasons at node (ID: 0e206a13d87f7d2f8b01010d06fa0b550b64bbb8773293ab52e0686e, IP: 172.19.100.51) over the last time period. To see more information about the Workers killed on this node, use `ray logs raylet.out -ip 172.19.100.51` (raylet) (raylet) Refer to the documentation on how to address the out of memory issue: https://docs.ray.io/en/latest/ray-core/scheduling/ray-oom-prevention.html. Consider provisioning more memory on this node or reducing task parallelism by requesting more CPUs per task. To adjust the kill threshold, set the environment variable `RAY_memory_usage_threshold` when starting Ray. To disable worker killing, set the environment variable `RAY_memory_monitor_refresh_ms` to zero. (raylet) [2023-12-08 16:21:28,835 E 602035 602035] (raylet) node_manager.cc:3035: 7 Workers (tasks / actors) killed due to memory pressure (OOM), 0 Workers crashed due to other reasons at node (ID: 0e206a13d87f7d2f8b01010d06fa0b550b64bbb8773293ab52e0686e, IP: 172.19.100.51) over the last time period. To see more information about the Workers killed on this node, use `ray logs raylet.out -ip 172.19.100.51` (raylet) (raylet) Refer to the documentation on how to address the out of memory issue: https://docs.ray.io/en/latest/ray-core/scheduling/ray-oom-prevention.html. Consider provisioning more memory on this node or reducing task parallelism by requesting more CPUs per task. To adjust the kill threshold, set the environment variable `RAY_memory_usage_threshold` when starting Ray. To disable worker killing, set the environment variable `RAY_memory_monitor_refresh_ms` to zero.
Next, we use the predict method to forecast the next 48 days using the optimal hyperparameters.
fcst_df = nf.predict()
fcst_df.columns = fcst_df.columns.str.replace('-median', '')
fcst_df.head()Predicting DataLoader 0: 100%|██████████| 3/3 [00:00<00:00, 164.16it/s]
Predicting DataLoader 0: 100%|██████████| 3/3 [00:00<00:00, 13.89it/s]| ds | AutoNHITS | AutoNHITS-lo-90 | AutoNHITS-lo-80 | AutoNHITS-hi-80 | AutoNHITS-hi-90 | AutoLSTM | AutoLSTM-lo-90 | AutoLSTM-lo-80 | AutoLSTM-hi-80 | AutoLSTM-hi-90 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| unique_id | |||||||||||
| H1 | 749 | 550.545288 | 491.368347 | 484.838226 | 640.832520 | 658.631592 | 581.597534 | 510.460632 | 533.967041 | 660.153076 | 690.976379 |
| H1 | 750 | 549.216736 | 491.054932 | 484.474243 | 639.552002 | 657.615967 | 530.324402 | 440.821899 | 472.254272 | 622.214539 | 653.435913 |
| H1 | 751 | 528.075989 | 466.917053 | 463.002289 | 621.197205 | 642.255005 | 487.045593 | 383.502045 | 423.310974 | 594.273071 | 627.640320 |
| H1 | 752 | 486.842255 | 418.012115 | 419.017242 | 585.653259 | 611.903809 | 457.408081 | 347.901093 | 390.807495 | 569.789062 | 604.200012 |
| H1 | 753 | 452.015930 | 371.543884 | 379.539215 | 558.845154 | 590.465942 | 441.641418 | 333.888611 | 374.730621 | 557.401978 | 595.008484 |
StatsForecast.plot(Y_df, fcst_df, engine='matplotlib', max_insample_length=48 * 3, level=[80, 90])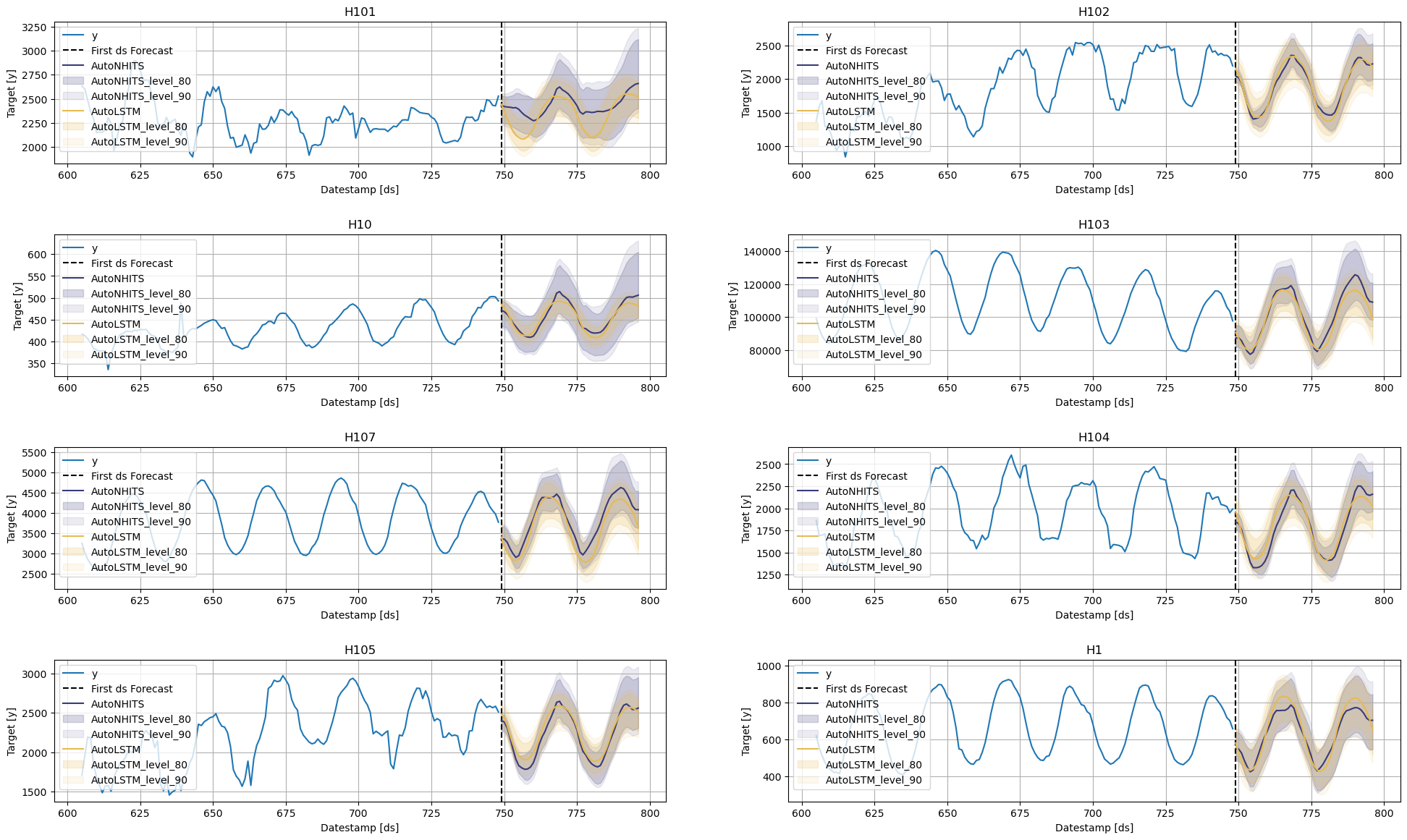
The StatsForecast.plot allows for further customization. For example, plot the results of the different models and unique ids.
# Plot to unique_ids and some selected models
StatsForecast.plot(Y_df, fcst_df, models=["AutoLSTM"], unique_ids=["H107", "H104"], level=[80, 90], engine='matplotlib')
# Explore other models
StatsForecast.plot(Y_df, fcst_df, models=["AutoNHITS"], unique_ids=["H10", "H105"], level=[80, 90], engine='matplotlib')
5. Evaluate the model’s performance
In previous steps, we’ve taken our historical data to predict the future. However, to asses its accuracy we would also like to know how the model would have performed in the past. To assess the accuracy and robustness of your models on your data perform Cross-Validation.
With time series data, Cross Validation is done by defining a sliding window across the historical data and predicting the period following it. This form of cross-validation allows us to arrive at a better estimation of our model’s predictive abilities across a wider range of temporal instances while also keeping the data in the training set contiguous as is required by our models.
The following graph depicts such a Cross Validation Strategy:

Tip
Setting n_windows=1 mirrors a traditional train-test split with our historical data serving as the training set and the last 48 hours serving as the testing set.
The cross_validation method from the NeuralForecast class takes the following arguments.
df: training data framestep_size(int): step size between each window. In other words: how often do you want to run the forecasting processes.n_windows(int): number of windows used for cross validation. In other words: what number of forecasting processes in the past do you want to evaluate.
from neuralforecast.auto import AutoNHITS, AutoLSTM
config_nhits = {
"input_size": tune.choice([48, 48*2, 48*3]), # Length of input window
"start_padding_enabled": True,
"n_blocks": 5*[1], # Length of input window
"mlp_units": 5 * [[64, 64]], # Length of input window
"n_pool_kernel_size": tune.choice([5*[1], 5*[2], 5*[4],
[8, 4, 2, 1, 1]]), # MaxPooling Kernel size
"n_freq_downsample": tune.choice([[8, 4, 2, 1, 1],
[1, 1, 1, 1, 1]]), # Interpolation expressivity ratios
"learning_rate": tune.loguniform(1e-4, 1e-2), # Initial Learning rate
"scaler_type": tune.choice([None]), # Scaler type
"max_steps": tune.choice([1000]), # Max number of training iterations
"batch_size": tune.choice([1, 4, 10]), # Number of series in batch
"windows_batch_size": tune.choice([128, 256, 512]), # Number of windows in batch
"random_seed": tune.randint(1, 20), # Random seed
}
config_lstm = {
"input_size": tune.choice([48, 48*2, 48*3]), # Length of input window
"encoder_hidden_size": tune.choice([64, 128]), # Hidden size of LSTM cells
"encoder_n_layers": tune.choice([2,4]), # Number of layers in LSTM
"learning_rate": tune.loguniform(1e-4, 1e-2), # Initial Learning rate
"scaler_type": tune.choice(['robust']), # Scaler type
"max_steps": tune.choice([500, 1000]), # Max number of training iterations
"batch_size": tune.choice([1, 4]), # Number of series in batch
"random_seed": tune.randint(1, 20), # Random seed
}
nf = NeuralForecast(
models=[
AutoNHITS(h=48, config=config_nhits, loss=MQLoss(), num_samples=5),
AutoLSTM(h=48, config=config_lstm, loss=MQLoss(), num_samples=2),
],
freq='H'
)cv_df = nf.cross_validation(Y_df, n_windows=2)Global seed set to 4
Global seed set to 19The cv_df object is a new data frame that includes the following columns:
unique_id: identifies each time seriesds: datestamp or temporal indexcutoff: the last datestamp or temporal index for the n_windows. If n_windows=1, then one unique cuttoff value, if n_windows=2 then two unique cutoff values.y: true value"model": columns with the model’s name and fitted value.
cv_df.columns = cv_df.columns.str.replace('-median', '')cv_df.head()| unique_id | ds | cutoff | AutoNHITS | AutoNHITS-lo-90 | AutoNHITS-lo-80 | AutoNHITS-hi-80 | AutoNHITS-hi-90 | AutoLSTM | AutoLSTM-lo-90 | AutoLSTM-lo-80 | AutoLSTM-hi-80 | AutoLSTM-hi-90 | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | H1 | 700 | 699 | 646.881714 | 601.402893 | 626.471008 | 672.432617 | 683.847778 | 633.707031 | 365.139832 | 407.289246 | 871.474976 | 925.476196 | 684.0 |
| 1 | H1 | 701 | 699 | 635.608643 | 595.042908 | 612.889771 | 669.565979 | 679.472900 | 632.455017 | 365.303131 | 406.472992 | 869.484985 | 922.926514 | 619.0 |
| 2 | H1 | 702 | 699 | 592.663940 | 564.124390 | 566.502319 | 648.286072 | 647.859253 | 633.002502 | 365.147522 | 407.174866 | 868.677979 | 925.269409 | 565.0 |
| 3 | H1 | 703 | 699 | 543.364563 | 516.760742 | 517.990234 | 603.099182 | 601.462280 | 633.903503 | 364.976746 | 408.498779 | 869.797180 | 925.993164 | 532.0 |
| 4 | H1 | 704 | 699 | 498.051178 | 461.069489 | 474.206360 | 540.752563 | 555.169739 | 634.015991 | 363.384155 | 408.305298 | 870.154297 | 920.329224 | 495.0 |
for cutoff in cv_df['cutoff'].unique():
StatsForecast.plot(
Y_df,
cv_df.query('cutoff == @cutoff').drop(columns=['y', 'cutoff']),
max_insample_length=48 * 4,
unique_ids=['H185'],
engine='matplotlib'
)Now, let’s evaluate the models’ performance.
from datasetsforecast.losses import mse, mae, rmse
from datasetsforecast.evaluation import accuracy
Warning
You can also use Mean Average Percentage Error (MAPE), however for granular forecasts, MAPE values are extremely hard to judge and not useful to assess forecasting quality.
Create the data frame with the results of the evaluation of your cross-validation data frame using a Mean Squared Error metric.
evaluation_df = accuracy(cv_df, [mse, mae, rmse], agg_by=['unique_id'])
evaluation_df['best_model'] = evaluation_df.drop(columns=['metric', 'unique_id']).idxmin(axis=1)
evaluation_df.head()| metric | unique_id | AutoNHITS | AutoLSTM | best_model | |
|---|---|---|---|---|---|
| 0 | mae | H1 | 38.259457 | 131.158150 | AutoNHITS |
| 1 | mae | H10 | 14.044900 | 32.972164 | AutoNHITS |
| 2 | mae | H100 | 254.464978 | 281.836064 | AutoNHITS |
| 3 | mae | H101 | 257.810841 | 148.341771 | AutoLSTM |
| 4 | mae | H102 | 176.114826 | 472.413350 | AutoNHITS |
Create a summary table with a model column and the number of series where that model performs best.
summary_df = evaluation_df.groupby(['metric', 'best_model']).size().sort_values().to_frame()
summary_df = summary_df.reset_index()
summary_df.columns = ['metric', 'model', 'nr. of unique_ids']
summary_df| metric | model | nr. of unique_ids | |
|---|---|---|---|
| 0 | mae | AutoLSTM | 1 |
| 1 | mse | AutoLSTM | 1 |
| 2 | rmse | AutoLSTM | 1 |
| 3 | mae | AutoNHITS | 9 |
| 4 | mse | AutoNHITS | 9 |
| 5 | rmse | AutoNHITS | 9 |
summary_df.query('metric == "mse"')| metric | model | nr. of unique_ids | |
|---|---|---|---|
| 1 | mse | AutoLSTM | 1 |
| 4 | mse | AutoNHITS | 9 |
You can further explore your results by plotting the unique_ids where a specific model wins.
nhits_ids = evaluation_df.query('best_model == "AutoNHITS" and metric == "mse"')['unique_id'].unique()
StatsForecast.plot(Y_df, fcst_df, unique_ids=nhits_ids, engine='matplotlib')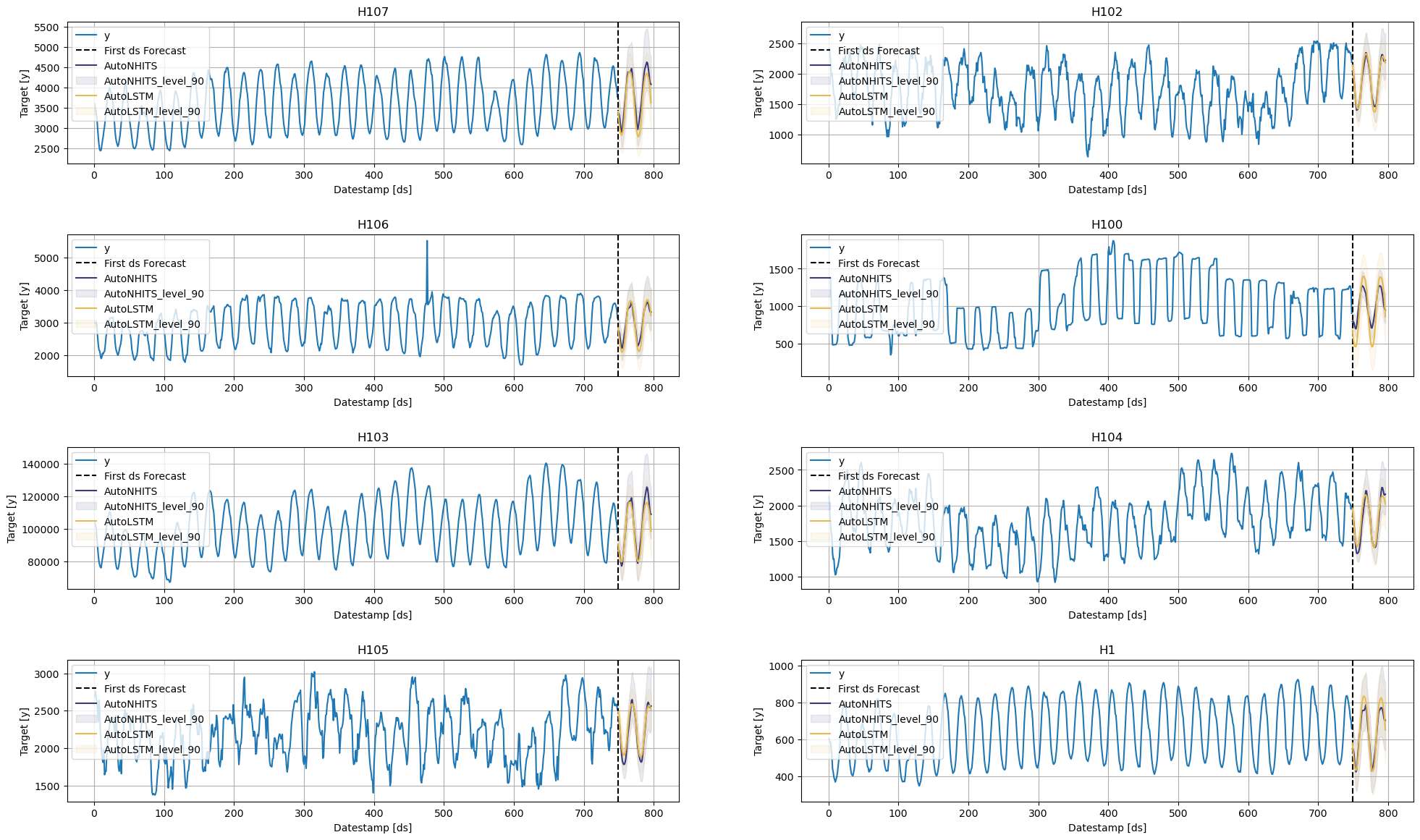
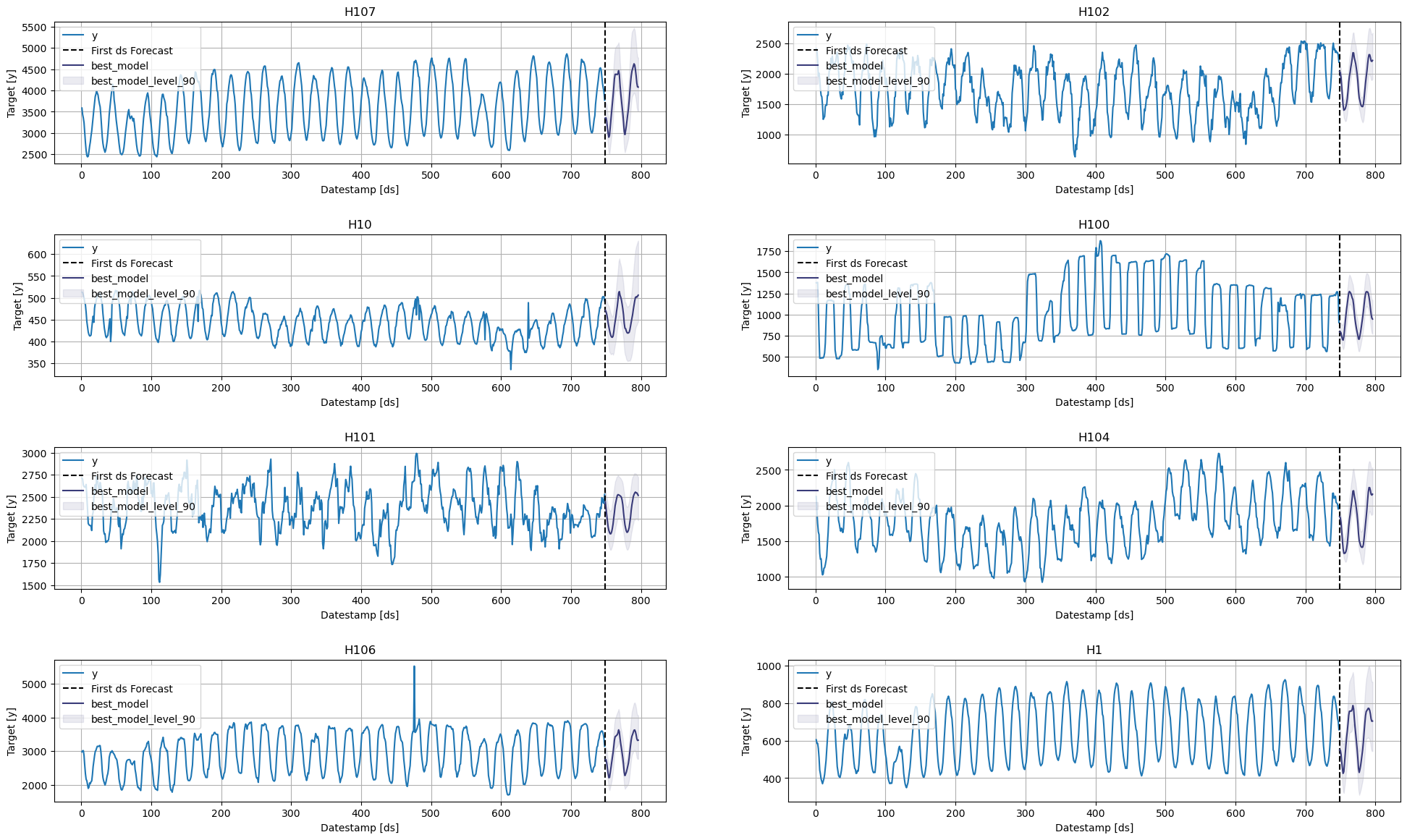
6. Select the best model for every unique series
Define a utility function that takes your forecast’s data frame with the predictions and the evaluation data frame and returns a data frame with the best possible forecast for every unique_id.
def get_best_model_forecast(forecasts_df, evaluation_df, metric):
df = forecasts_df.set_index('ds', append=True).stack().to_frame().reset_index(level=2) # Wide to long
df.columns = ['model', 'best_model_forecast']
df = df.join(evaluation_df.query('metric == @metric').set_index('unique_id')[['best_model']])
df = df.query('model.str.replace("-lo-90|-hi-90", "", regex=True) == best_model').copy()
df.loc[:, 'model'] = [model.replace(bm, 'best_model') for model, bm in zip(df['model'], df['best_model'])]
df = df.drop(columns='best_model').set_index('model', append=True).unstack()
df.columns = df.columns.droplevel()
df = df.reset_index(level=1)
return dfCreate your production-ready data frame with the best forecast for every unique_id.
prod_forecasts_df = get_best_model_forecast(fcst_df, evaluation_df, metric='mse')
prod_forecasts_df.head()| model | ds | best_model | best_model-hi-90 | best_model-lo-90 |
|---|---|---|---|---|
| unique_id | ||||
| H1 | 749 | 550.545288 | 658.631592 | 491.368347 |
| H1 | 750 | 549.216736 | 657.615967 | 491.054932 |
| H1 | 751 | 528.075989 | 642.255005 | 466.917053 |
| H1 | 752 | 486.842255 | 611.903809 | 418.012115 |
| H1 | 753 | 452.015930 | 590.465942 | 371.543884 |
Plot the results.
StatsForecast.plot(Y_df, prod_forecasts_df, level=[90], engine='matplotlib')