from torcheval.metrics import MulticlassAccuracy
from datasets import load_dataset,load_dataset_builder
mpl.rcParams['image.cmap'] = 'gray_r'
logging.disable(logging.WARNING)Denoising Diffusion Probabilistic Models with miniai
- skip_showdoc: true
Imports
Load the dataset
xl,yl = 'image','label'
name = "fashion_mnist"
dsd = load_dataset(name)
@inplace
def transformi(b): b[xl] = [F.pad(TF.to_tensor(o), (2,2,2,2)) for o in b[xl]]
bs = 128
tds = dsd.with_transform(transformi)
dls = DataLoaders.from_dd(tds, bs, num_workers=8)dt = dls.train
xb,yb = next(iter(dt))show_images(xb[:16], imsize=1.5)
betamin,betamax,n_steps = 0.0001,0.02,1000
beta = torch.linspace(betamin, betamax, n_steps)
alpha = 1.-beta
alphabar = alpha.cumprod(dim=0)
sigma = beta.sqrt()plt.plot(beta);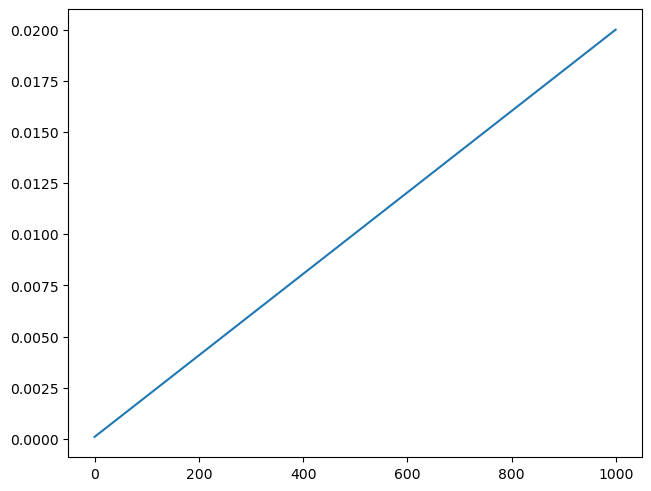
plt.plot(sigma);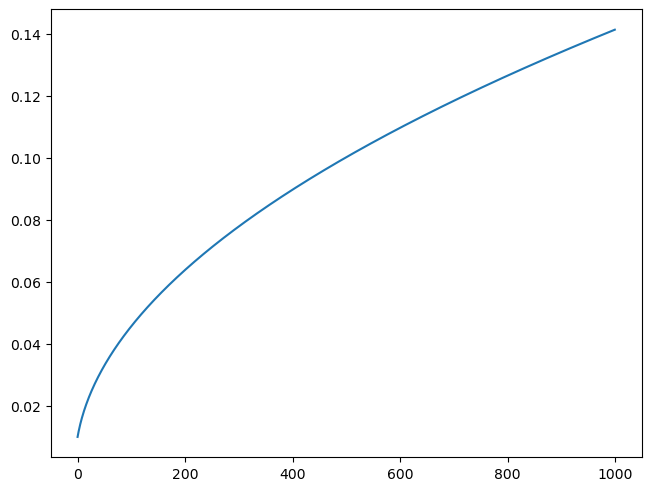
plt.plot(alphabar);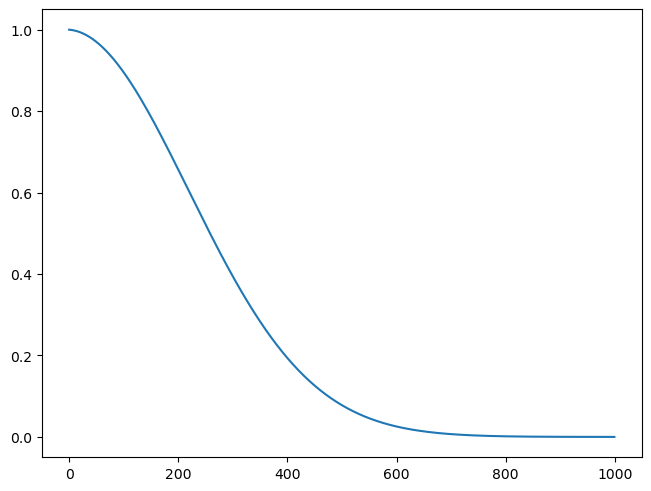
Exported source
def noisify(x0, ᾱ):
device = x0.device
n = len(x0)
t = torch.randint(0, n_steps, (n,), dtype=torch.long)
ε = torch.randn(x0.shape, device=device)
ᾱ_t = ᾱ[t].reshape(-1, 1, 1, 1).to(device)
xt = ᾱ_t.sqrt()*x0 + (1-ᾱ_t).sqrt()*ε
return (xt, t.to(device)), ε(xt,t),ε = noisify(xb[:25],alphabar)
ttensor([ 26, 335, 620, 924, 950, 113, 378, 14, 210, 954, 231, 572, 315, 295, 567, 706, 749, 876, 73, 111, 899, 213, 541, 769, 287])titles = fc.map_ex(t, '{}')
show_images(xt, imsize=1.5, titles=titles)
Training
Exported source
from diffusers import UNet2DModelExported source
@torch.no_grad()
def sample(model, sz, alpha, alphabar, sigma, n_steps):
device = next(model.parameters()).device
x_t = torch.randn(sz, device=device)
preds = []
for t in reversed(range(n_steps)):
t_batch = torch.full((x_t.shape[0],), t, device=device, dtype=torch.long)
z = (torch.randn(x_t.shape) if t > 0 else torch.zeros(x_t.shape)).to(device)
ᾱ_t1 = alphabar[t-1] if t > 0 else torch.tensor(1)
b̄_t = 1 - alphabar[t]
b̄_t1 = 1 - ᾱ_t1
x_0_hat = ((x_t - b̄_t.sqrt() * learn.model((x_t, t_batch)))/alphabar[t].sqrt()).clamp(-1,1)
x_t = x_0_hat * ᾱ_t1.sqrt()*(1-alpha[t])/b̄_t + x_t * alpha[t].sqrt()*b̄_t1/b̄_t + sigma[t]*z
preds.append(x_t.cpu())
return predsExported source
class DDPMCB(Callback):
order = DeviceCB.order+1
def __init__(self, n_steps, beta_min, beta_max):
super().__init__()
fc.store_attr()
self.beta = torch.linspace(self.beta_min, self.beta_max, self.n_steps)
self.α = 1. - self.beta
self.ᾱ = torch.cumprod(self.α, dim=0)
self.σ = self.beta.sqrt()
def before_batch(self, learn): learn.batch = noisify(learn.batch[0], self.ᾱ)
def sample(self, model, sz): return sample(model, sz, self.α, self.ᾱ, self.σ, self.n_steps)Exported source
class UNet(UNet2DModel):
def forward(self, x): return super().forward(*x).sampleddpm_cb = DDPMCB(n_steps=1000, beta_min=0.0001, beta_max=0.02)model = UNet(in_channels=1, out_channels=1, block_out_channels=(16, 32, 64, 64), norm_num_groups=8)
learn = TrainLearner(model, dls, nn.MSELoss())
learn.fit(train=False, cbs=[ddpm_cb,SingleBatchCB()])
(xt,t),ε = learn.batch
show_images(xt[:25], titles=fc.map_ex(t[:25], '{}'), imsize=1.5)
lr = 5e-3
epochs = 3
tmax = epochs * len(dls.train)
sched = partial(lr_scheduler.OneCycleLR, max_lr=lr, total_steps=tmax)
cbs = [ddpm_cb, DeviceCB(), ProgressCB(plot=True), MetricsCB(), BatchSchedCB(sched)]model = UNet(in_channels=1, out_channels=1, block_out_channels=(16, 32, 64, 128), norm_num_groups=8)Exported source
def init_ddpm(model):
for o in model.down_blocks:
for p in o.resnets:
p.conv2.weight.data.zero_()
for p in fc.L(o.downsamplers): init.orthogonal_(p.conv.weight)
for o in model.up_blocks:
for p in o.resnets: p.conv2.weight.data.zero_()
model.conv_out.weight.data.zero_()init_ddpm(model)opt_func = partial(optim.Adam, eps=1e-5)learn = TrainLearner(model, dls, nn.MSELoss(), lr=lr, cbs=cbs, opt_func=opt_func)learn.fit(epochs)| loss | epoch | train |
|---|---|---|
| 0.131 | 0 | train |
| 0.024 | 0 | eval |
| 0.022 | 1 | train |
| 0.022 | 1 | eval |
| 0.019 | 2 | train |
| 0.020 | 2 | eval |
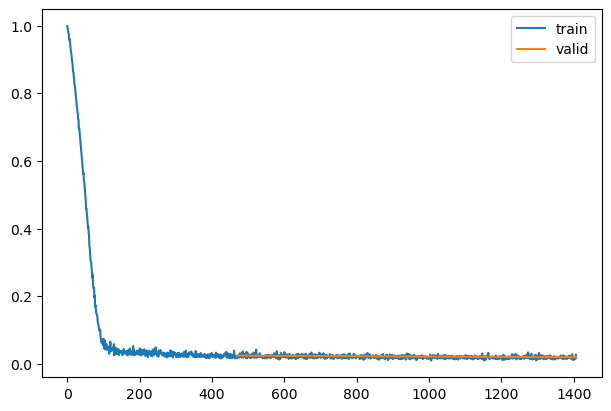
mdl_path = Path('models')torch.save(learn.model, mdl_path/'fashion_ddpm2.pkl')learn.model = torch.load(mdl_path/'fashion_ddpm2.pkl')Sampling
samples = ddpm_cb.sample(learn.model, (16, 1, 32, 32))show_images(samples[-1], figsize=(5,5))
Mixed Precision
bs = 512next(iter(DataLoader(tds['train'], batch_size=2))){'image': tensor([[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]]]),
'label': tensor([9, 0])}Exported source
def collate_ddpm(b): return noisify(default_collate(b)[xl], alphabar)
def dl_ddpm(ds): return DataLoader(ds, batch_size=bs, collate_fn=collate_ddpm, num_workers=4)dls = DataLoaders(dl_ddpm(tds['train']), dl_ddpm(tds['test']))Exported source
class MixedPrecision(TrainCB):
order = DeviceCB.order+10
def before_fit(self, learn): self.scaler = torch.cuda.amp.GradScaler()
def before_batch(self, learn):
self.autocast = torch.autocast("cuda", dtype=torch.float16)
self.autocast.__enter__()
def after_loss(self, learn): self.autocast.__exit__(None, None, None)
def backward(self, learn): self.scaler.scale(learn.loss).backward()
def step(self, learn):
self.scaler.step(learn.opt)
self.scaler.update()lr = 1e-2
epochs = 3
tmax = epochs * len(dls.train)
sched = partial(lr_scheduler.OneCycleLR, max_lr=lr, total_steps=tmax)
cbs = [DeviceCB(), MixedPrecision(), ProgressCB(plot=True), MetricsCB(), BatchSchedCB(sched)]
model = UNet(in_channels=1, out_channels=1, block_out_channels=(16, 32, 64, 128), norm_num_groups=8)
init_ddpm(model)
learn = Learner(model, dls, nn.MSELoss(), lr=lr, cbs=cbs, opt_func=opt_func)learn.fit(epochs)| loss | epoch | train |
|---|---|---|
| nan | 0 | train |
| nan | 0 | eval |
| nan | 1 | train |
| nan | 1 | eval |
| nan | 2 | train |
| nan | 2 | eval |
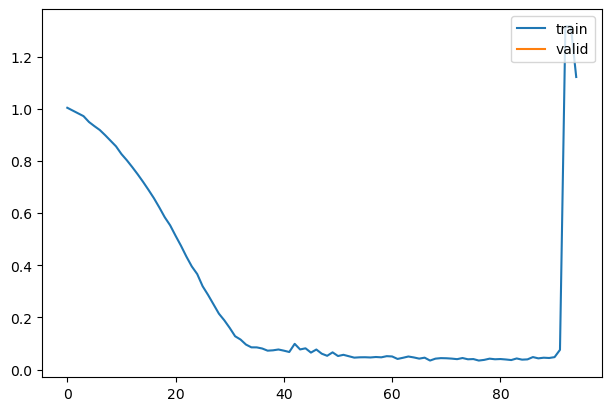
samples = sample(learn.model, (32, 1, 32, 32), alpha, alphabar, sigma, n_steps)show_images(samples[-1][:25], imsize=1.5)
torch.save(learn.model, 'models/fashion_ddpm_mp.pkl')Accelerate
pip install accelerate before running this section.
Exported source
from accelerate import AcceleratorExported source
class AccelerateCB(TrainCB):
order = DeviceCB.order+10
def __init__(self, n_inp=1, mixed_precision="fp16"):
super().__init__(n_inp=n_inp)
self.acc = Accelerator(mixed_precision=mixed_precision)
def before_fit(self, learn):
learn.model,learn.opt,learn.dls.train,learn.dls.valid = self.acc.prepare(
learn.model, learn.opt, learn.dls.train, learn.dls.valid)
def backward(self, learn): self.acc.backward(learn.loss)Exported source
def noisify(x0, ᾱ):
device = x0.device
n = len(x0)
t = torch.randint(0, n_steps, (n,), dtype=torch.long)
ε = torch.randn(x0.shape, device=device)
ᾱ_t = ᾱ[t].reshape(-1, 1, 1, 1).to(device)
xt = ᾱ_t.sqrt()*x0 + (1-ᾱ_t).sqrt()*ε
return xt, t.to(device), εdls = DataLoaders(dl_ddpm(tds['train']), dl_ddpm(tds['test']))Exported source
class DDPMCB2(Callback):
def after_predict(self, learn): learn.preds = learn.preds.samplemodel = UNet2DModel(in_channels=1, out_channels=1, block_out_channels=(16, 32, 64, 128), norm_num_groups=8)
init_ddpm(model)
cbs = [DDPMCB2(), DeviceCB(), ProgressCB(plot=True), MetricsCB(), BatchSchedCB(sched), AccelerateCB(n_inp=2)]
learn = Learner(model, dls, nn.MSELoss(), lr=lr, cbs=cbs, opt_func=opt_func)learn.fit(epochs)| loss | epoch | train |
|---|---|---|
| 0.201 | 0 | train |
| 0.031 | 0 | eval |
| 0.025 | 1 | train |
| 0.022 | 1 | eval |
| 0.022 | 2 | train |
| 0.021 | 2 | eval |
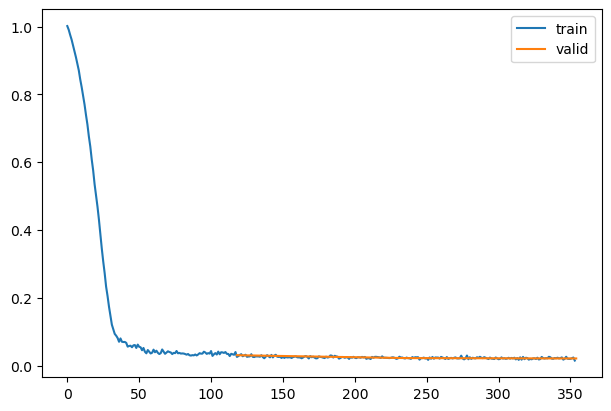
A sneaky trick
Exported source
class MultDL:
def __init__(self, dl, mult=2): self.dl,self.mult = dl,mult
def __len__(self): return len(self.dl)*self.mult
def __iter__(self):
for o in self.dl:
for i in range(self.mult): yield odls.train = MultDL(dls.train)