The result is nans everywhere. So maybe the scale of our matrix was too big, and we need to have smaller weights? But if we use too small weights, we will have the opposite problem—the scale of our activations will go from 1 to 0.1, and after 50 layers we’ll be left with zeros everywhere:
x = torch.randn(200, 100)for i inrange(50): x = x @ (torch.randn(100,100) *0.01)x[0:5,0:5]
So we have to scale our weight matrices exactly right so that the standard deviation of our activations stays at 1. We can compute the exact value to use mathematically, as illustrated by Xavier Glorot and Yoshua Bengio in “Understanding the Difficulty of Training Deep Feedforward Neural Networks”. The right scale for a given layer is \(1/\sqrt{n_{in}}\), where \(n_{in}\) represents the number of inputs.
x = torch.randn(200, 100)for i inrange(50): x = x @ (torch.randn(100,100) *0.1)x[0:5,0:5]
Variance is the average of how far away each data point is from the mean. E.g.:
t = torch.tensor([1.,2.,4.,18])
m = t.mean(); m
tensor(6.25)
(t-m).mean()
tensor(0.)
Oops. We can’t do that. Because by definition the positives and negatives cancel out. So we can fix that in one of (at least) two ways:
Variance
(t-m).pow(2).mean()
tensor(47.19)
(t-m).pow(2).sqrt().mean()
tensor(5.88)
Mean absolute difference
(t-m).abs().mean()
tensor(5.88)
But the first of these is now a totally different scale, since we squared. So let’s undo that at the end.
Standard deviation (std)
(t-m).pow(2).mean().sqrt()
tensor(6.87)
They’re still different. Why?
Note that we have one outlier (18). In the version where we square everything, it makes that much bigger than everything else.
(t-m).pow(2).mean() is refered to as variance. It’s a measure of how spread out the data is, and is particularly sensitive to outliers.
When we take the sqrt of the variance, we get the standard deviation. Since it’s on the same kind of scale as the original data, it’s generally more interpretable. However, since sqrt(1)==1, it doesn’t much matter which we use when talking about unit variance for initializing neural nets.
The standard deviation represents if the data stays close to the mean or on the contrary gets values that are far away. It’s computed by the following formula:
where m is the mean and \(\sigma\) (the greek letter sigma) is the standard deviation. Here we have a mean of 0, so it’s just the square root of the mean of x squared.
(t-m).abs().mean() is referred to as the mean absolute deviation. It isn’t used nearly as much as it deserves to be, because mathematicians don’t like how awkward it is to work with. But that shouldn’t stop us, because we have computers and stuff.
Here’s a useful thing to note about variance:
(t-m).pow(2).mean(), (t*t).mean() - (m*m)
(tensor(47.19), tensor(47.19))
You can see why these are equal if you want to work thru the algebra. Or not.
But, what’s important here is that the latter is generally much easier to work with. In particular, you only have to track two things: the sum of the data, and the sum of squares of the data. Whereas in the first form you actually have to go thru all the data twice (once to calculate the mean, once to calculate the differences).
From now on, you’re not allowed to look at an equation (or especially type it in LaTeX) without also typing it in Python and actually calculating some values. Ideally, you should also plot some values.
Finally, here is the Pearson correlation coefficient:
At the very beginning, our x vector has a mean of roughly 0. and a standard deviation of roughly 1. (since we picked it that way).
x = torch.randn(100)x.mean(), x.std()
(tensor(-0.03), tensor(1.05))
If we go back to y = a @ x and assume that we chose weights for a that also have a mean of 0, we can compute the standard deviation of y quite easily. Since it’s random, and we may fall on bad numbers, we repeat the operation 100 times.
mean,sqr =0.,0.for i inrange(100): x = torch.randn(100) a = torch.randn(512, 100) y = a @ x mean += y.mean().item() sqr += y.pow(2).mean().item()mean/100,sqr/100
(0.02379358373582363, 101.66621231079101)
Now that looks very close to the dimension of our matrix 100. And that’s no coincidence! When you compute y, you sum 100 product of one element of a by one element of x. So what’s the mean and the standard deviation of such a product? We can show mathematically that as long as the elements in a and the elements in x are independent, the mean is 0 and the std is 1. This can also be seen experimentally:
mean,sqr =0.,0.for i inrange(10000): x = torch.randn(1) a = torch.randn(1) y = a*x mean += y.item() sqr += y.pow(2).item()mean/10000,sqr/10000
(-0.008459147600694087, 0.9879768942045608)
Then we sum 100 of those things that have a mean of zero, and a mean of squares of 1, so we get something that has a mean of 0, and mean of square of 100, hence math.sqrt(100) being our magic number. If we scale the weights of the matrix and divide them by this math.sqrt(100), it will give us a y of scale 1, and repeating the product has many times as we want won’t overflow or vanish.
Kaiming/He init
(“He” is a Chinese surname and is pronouced like “Her”, not like “Hee”.)
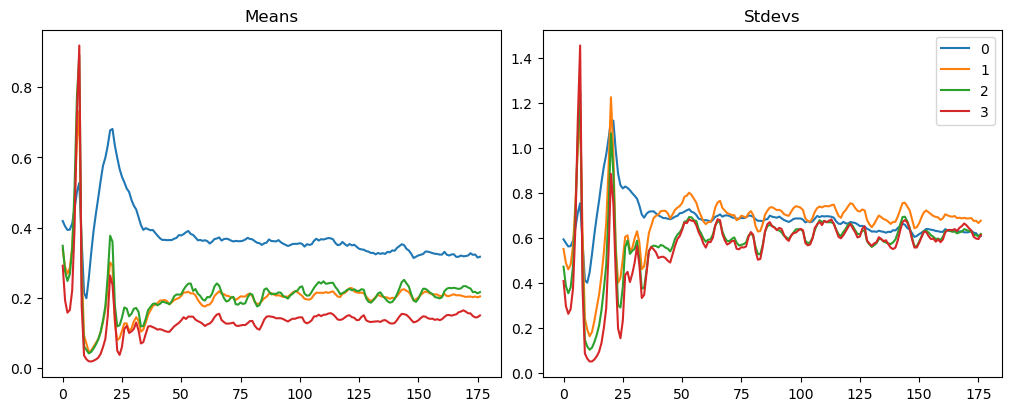
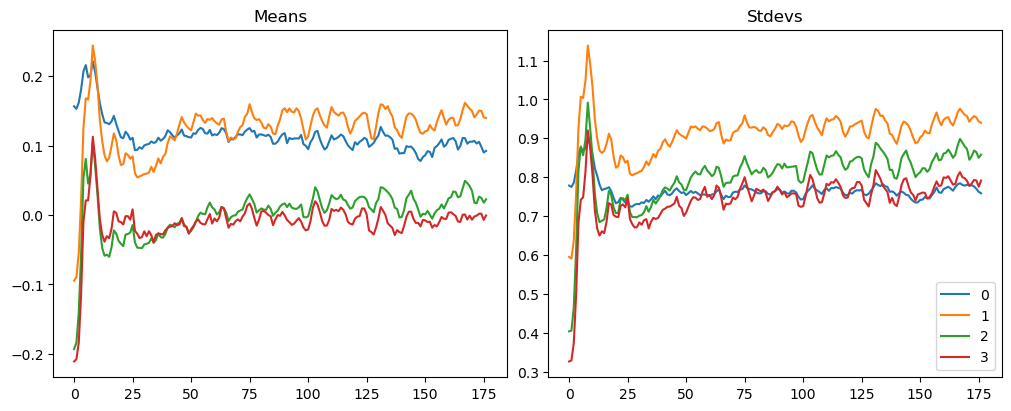
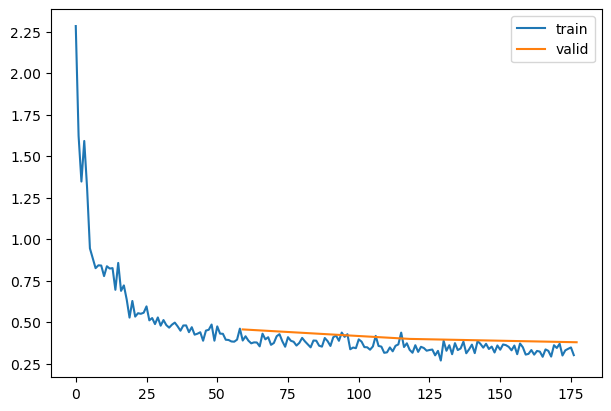
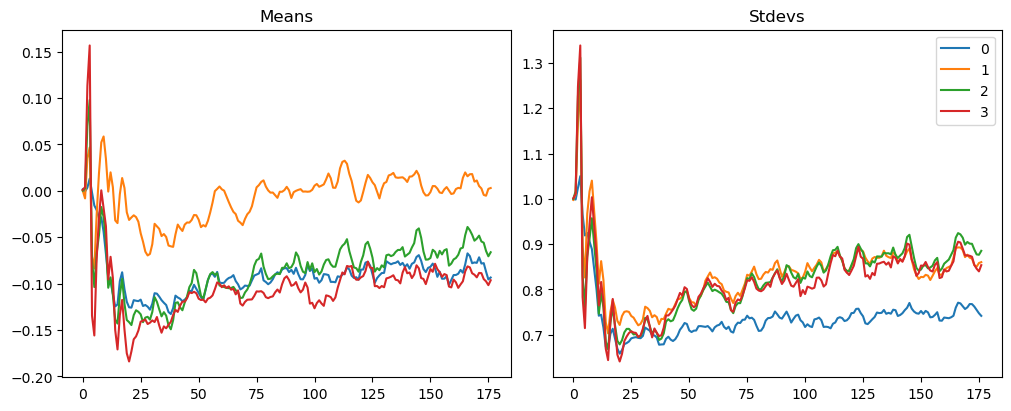
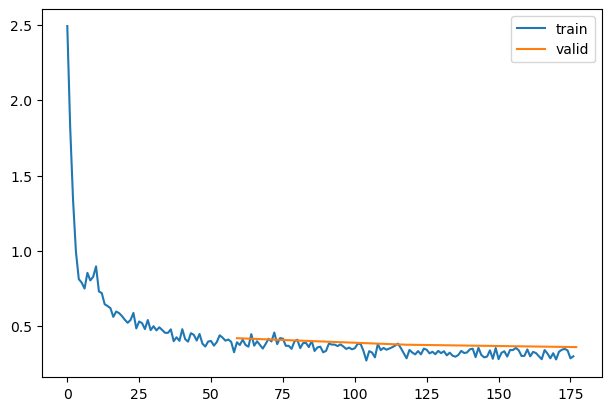
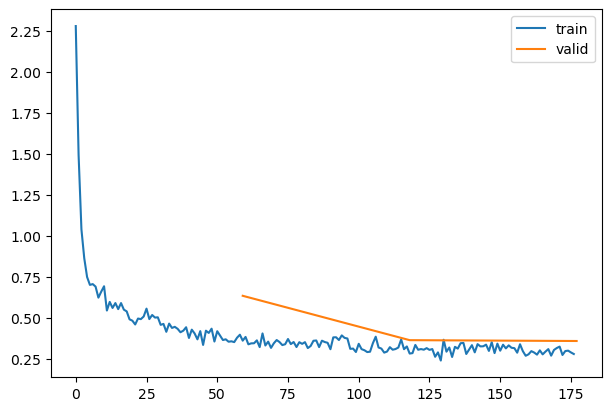
model = get_model(act_gr)relus = [o for o in model.modules() ifisinstance(o, GeneralRelu)]convs = [o for o in model.modules() ifisinstance(o, nn.Conv2d)]
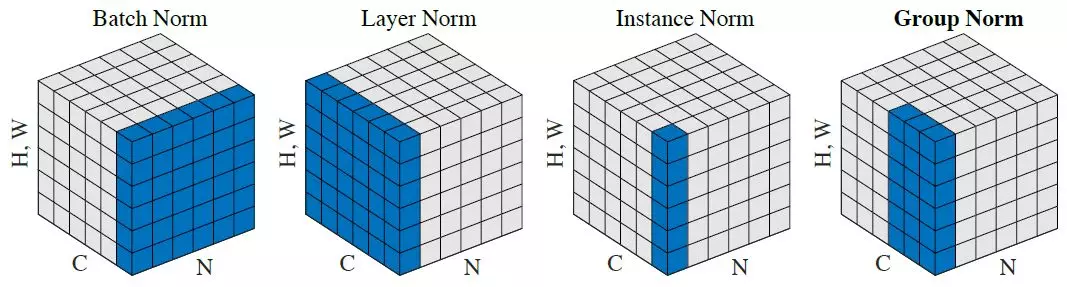
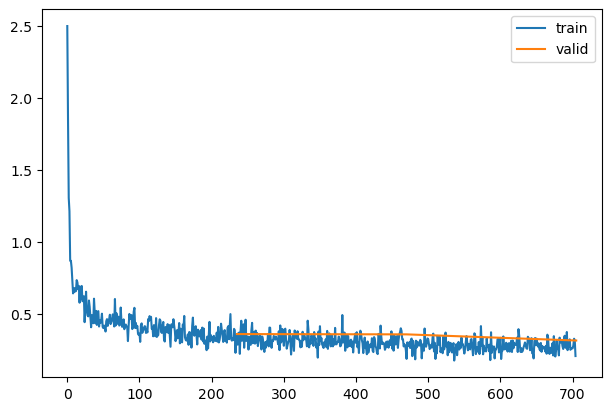
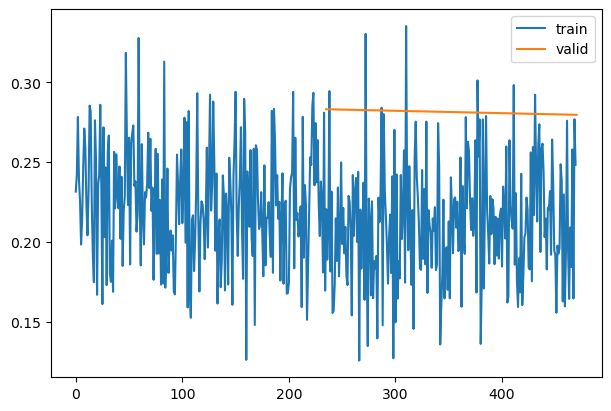
Training Deep Neural Networks is complicated by the fact that the distribution of each layer’s inputs changes during training, as the parameters of the previous layers change. This slows down the training by requiring lower learning rates and careful parameter initialization… We refer to this phenomenon as internal covariate shift, and address the problem by normalizing layer inputs.
Their proposal is:
Making normalization a part of the model architecture and performing the normalization for each training mini-batch. Batch Normalization allows us to use much higher learning rates and be less careful about initialization.