!pip list | grep ipywidgetsipywidgets 8.0.4A neural network is just a mathematical function. In the most standard kind of neural network, the function:
This represents one “layer”. Then these three steps are repeated, using the outputs of the previous layer as the inputs to the next layer. Initially, the parameters in this function are selected randomly. Therefore a newly created neural network doesn’t do anything useful at all – it’s just random!
To get the function to “learn” to do something useful, we have to change the parameters to make them “better” in some way. We do this using gradient descent. Let’s see how this works…
!pip list | grep ipywidgetsipywidgets 8.0.4import ipywidgets as widgetsbtn_upload = widgets.FileUpload(
button_style='success',
description='Upload',
accept='', # Accepted file extension e.g. '.txt', '.pdf', 'image/*', 'image/*,.pdf'
multiple=False # True to accept multiple files upload else False
)
display(btn_upload)def plot_function(f, title=None, min=-2.1, max=2.1, color='r', ylim=None):
import numpy as np, matplotlib.pyplot as plt
from fastai.basics import torch
x = torch.linspace(min,max, 100)[:,None]
if ylim: plt.ylim(ylim)
plt.rc('figure', dpi=90)
plt.plot(x, f(x), color)
if title is not None: plt.title(title)from ipywidgets import interact
import numpy as np, matplotlib.pyplot as plt
from fastai.basics import *To learn how gradient descent works, we’re going to start by fitting a quadratic, since that’s a function most of us are probably more familiar with than a neural network. Here’s the quadratic we’re going to try to fit:
def f(x): return 3*x**2 + 2*x + 1
plot_function(f, "$3x^2 + 2x + 1$")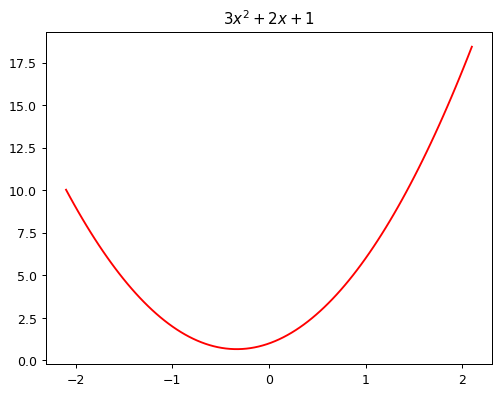
This quadratic is of the form \(ax^2+bx+c\), with parameters \(a=3\), \(b=2\), \(c=1\). To make it easier to try out different quadratics for fitting a model to the data we’ll create, let’s create a function that calculates the value of a point on any quadratic:
def quad(a, b, c, x): return a*x**2 + b*x + cquad(3,2,1, 1.5)10.75If we fix some particular values of a, b, and c, then we’ll have made a quadratic. To fix values passed to a function in python, we use the partial function, like so:
from functools import partialdef mk_quad(a,b,c): return partial(quad, a,b,c)So for instance, we can recreate our previous quadratic:
f2 = mk_quad(3,2,1)
plot_function(f2)
Now let’s simulate making some noisy measurements of our quadratic f. We’ll then use gradient descent to see if we can recreate the original function from the data.
Here’s a couple of functions to add some random noise to data:
from numpy.random import normal, seed, uniformdef noise(x, scale): return np.random.normal(scale=scale, size=x.shape)
def add_noise(x, mult, add): return x * (1+noise(x,mult)) + noise(x,add)Let’s use the now to create our noisy measurements based on the quadratic above:
np.random.seed(42)
x = torch.linspace(-2, 2, steps=20)[:,None]
y = add_noise(f(x), 0.15, 0.5)Here’s the first few values of each of x and y:
x[:5],y[:5](tensor([[-2.0000],
[-1.7895],
[-1.5789],
[-1.3684],
[-1.1579]]),
tensor([[10.4034],
[ 6.7691],
[ 5.8721],
[ 4.0551],
[ 2.3391]], dtype=torch.float64))As you can see, they’re tensors. A tensor is just like an array in numpy (if you’re not familiar with numpy, I strongly recommend reading this great book, because it’s a critical foundation for nearly all numeric programming in Python. Furthermore, PyTorch, which most researchers use for deep learning, is modeled closely on numpy.) A tensor can be a single number (a scalar or rank-0 tensor), a list of numbers (a vector or rank-1 tensor), a table of numbers (a matrix or rank-2 tensor), a table of tables of numbers (a rank-3 tensor), and so forth.
We’re not going to learn much about our data by just looking at the raw numbers, so let’s draw a picture:
plt.scatter(x,y);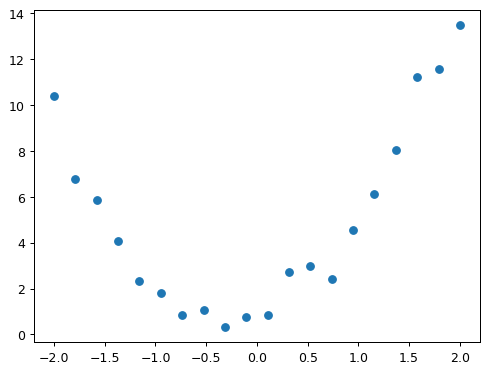
How do we find values of a, b, and c which fit this data? One approach is to try a few values and see what fits. Here’s a function which overlays a quadratic on top of our data, along with some sliders to change a, b, and c, and see how it looks:
@interact(a=1.1, b=1.1, c=1.1)
def plot_quad(a, b, c):
plt.scatter(x,y)
plot_function(mk_quad(a,b,c), ylim=(-3,13))Reminder: If the sliders above aren’t working for you, that’s because the interactive features of this notebook don’t work in Kaggle’s Reader mode. They only work in Edit mode. Please click “Copy & Edit” in the top right of this window, then in the menu click Run and then Run all. Then you’ll be able to use all the interactive sliders in this notebook.
Try moving slider a a bit to the left. Does that look better or worse? How about if you move it a bit to the right? Find out which direction seems to improve the fit of the quadratic to the data, and move the slider a bit in that direction. Next, do the same for slider b: first figure out which direction improves the fit, then move it a bit in that direction. Then do the same for c.
OK, now go back to slider a and repeat the process. Do it again for b and c as well.
Did you notice that by going back and doing the sliders a second time that you were able to improve things a bit further? That’s an important insight – it’s only after changing b and c, for instance, that you realise that a actually needs some adjustment based on those new values.
One thing that’s making this tricky is that we don’t really have a great sense of whether our fit is really better or worse. It would be easier if we had a numeric measure of that. On easy metric we could use is mean absolute error – which is the distance from each data point to the curve:
def mae(preds, acts): return (torch.abs(preds-acts)).mean()We’ll update our interactive function to print this at the top for us.
Use this to repeat the approach we took before to try to find the best fit, but this time just use the value of the metric to decide which direction to move each slider, and how far to move it.
This time around, try doing it in the opposite order: c, then b, then a.
You’ll probably find that you have to go through the set of sliders a couple of times to get the best fit.
@interact(a=1.1, b=1.1, c=1.1)
def plot_quad(a, b, c):
f = mk_quad(a,b,c)
plt.scatter(x,y)
loss = mae(f(x), y)
plot_function(f, ylim=(-3,12), title=f"MAE: {loss:.2f}")In a modern neural network we’ll often have tens of millions of parameters to fit, or more, and thousands or millions of data points to fit them to. We’re not going to be able to do that by moving sliders around! We’ll need to automate this process.
Thankfully, that turns out to be pretty straightforward. We can use calculus to figure out, for each parameter, whether we should increase or decrease it.
Uh oh, calculus! If you haven’t touched calculus since school, you might be getting ready to run away at this point. But don’t worry, we don’t actually need much calculus at all. Just derivatives, which measure the rate of change of a function. We don’t even need to calculate them ourselves, because the computer will do it for us! If you’ve forgotten what a derivitive is, then watch the first three of these fantastic videos by Professor Dave. It’s only 15 minutes in total, so give it a go! Then come back here and we’ll continue on our journey…
The basic idea is this: if we know the gradient of our mae() function with respect to our parameters, a, b, and c, then that means we know how adjusting (for instance) a will change the value of mae(). If, say, a has a negative gradient, then we know that increasing a will decrease mae(). Then we know that’s what we need to do, since we trying to make mae() as low as possible.
So, we find the gradient of mae() for each of our parameters, and then adjust our parameters a bit in the opposite direction to the sign of the gradient.
To do this, first we need a function that takes all the parameters a, b, and c as a single vector input, and returns the value mae() based on those parameters:
def quad_mae(params):
f = mk_quad(*params)
return mae(f(x), y)Let’s try it:
quad_mae([1.1, 1.1, 1.1])tensor(2.3176, dtype=torch.float64)Yup, that’s the same as the starting mae() we had in our plot before.
We’re first going to do exactly the same thing as we did manually – pick some arbritrary starting point for our parameters. We’ll put them all into a single tensor:
abc = torch.tensor([1.1,1.1,1.1])To tell PyTorch that we want it to calculate gradients for these parameters, we need to call requires_grad_():
abc.requires_grad_()tensor([1.1000, 1.1000, 1.1000], requires_grad=True)We can now calculate mae(). Generally, when doing gradient descent, the thing we’re trying to minimise is called the loss:
loss = quad_mae(abc)
losstensor(2.3176, dtype=torch.float64, grad_fn=<MeanBackward0>)To get PyTorch to now calculate the gradients, we need to call backward()
loss.backward()The gradients will be stored for us in an attribute called grad:
abc.gradtensor([-1.3529, -0.0316, -0.5000])According to these gradients, all our parameters are a little low. So let’s increase them a bit. If we subtract the gradient, multiplied by a small number, that should improve them a bit:
with torch.no_grad():
abc -= abc.grad*0.01
loss = quad_mae(abc)
print(f'loss={loss:.2f} and {abc}')loss=2.30 and tensor([1.1135, 1.1003, 1.1050], requires_grad=True)Yes, our loss has gone down!
The “small number” we multiply is called the learning rate, and is the most important hyper-parameter to set when training a neural network.
BTW, you’ll see we had to wrap our calculation of the new parameters in with torch.no_grad(). That disables the calculation of gradients for any operations inside that context manager. We have to do that, because abc -= abc.grad*0.01 isn’t actually part of our quadratic model, so we don’t want derivitives to include that calculation.
We can use a loop to do a few more iterations of this:
for i in range(10):
loss = quad_mae(abc)
loss.backward()
with torch.no_grad(): abc -= abc.grad*0.01
print(f'step={i}; loss={loss:.2f} and {abc}')step=0; loss=2.30 and tensor([1.1406, 1.1009, 1.1150], requires_grad=True)
step=1; loss=2.26 and tensor([1.1812, 1.1019, 1.1300], requires_grad=True)
step=2; loss=2.19 and tensor([1.2353, 1.1032, 1.1500], requires_grad=True)
step=3; loss=2.11 and tensor([1.3029, 1.1047, 1.1750], requires_grad=True)
step=4; loss=2.01 and tensor([1.3841, 1.1066, 1.2050], requires_grad=True)
step=5; loss=1.88 and tensor([1.4788, 1.1088, 1.2400], requires_grad=True)
step=6; loss=1.74 and tensor([1.5868, 1.1119, 1.2790], requires_grad=True)
step=7; loss=1.58 and tensor([1.7080, 1.1158, 1.3220], requires_grad=True)
step=8; loss=1.40 and tensor([1.8415, 1.1215, 1.3680], requires_grad=True)
step=9; loss=1.24 and tensor([1.9861, 1.1301, 1.4160], requires_grad=True)As you can see, our loss keeps going down!
If you keep running this loop for long enough however, you’ll see that the loss eventually starts increasing for a while. That’s because once the parameters get close to the correct answer, our parameter updates will jump right over the correct answer! To avoid this, we need to decrease our learning rate as we train. This is done using a learning rate schedule, and can be automated in most deep learning frameworks, such as fastai and PyTorch.
But neural nets are much more convenient and powerful than this example showed, because we can learn much more than just a quadratic with them. How does that work?
The trick is that a neural network is a very expressive function. In fact – it’s infinitely expressive. A neural network can approximate any computable function, given enough parameters. A “computable function” can cover just about anything you can imagine: understand and translate human speech; paint a picture; diagnose a disease from medical imaging; write an essay; etc…
The way a neural network approximates a function actually turns out to be very simple. The key trick is to combine two extremely basic steps:
In PyTorch, the function \(max(x,0)\) is written as np.clip(x,0). The combination of a linear function and this max() is called a rectified linear function, and it can be implemented like this:
def rectified_linear(m,b,x):
y = m*x+b
return torch.clip(y, 0)Here’s what it looks like:
plot_function(partial(rectified_linear, 1,1))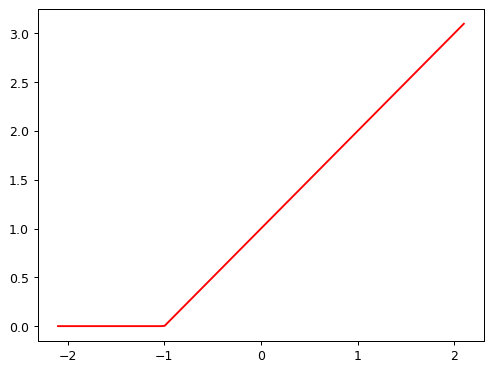
BTW, instead of torch.clip(y, 0.), we can instead use F.relu(x), which does exactly the same thing. In PyTorch, F refers to the torch.nn.functional module.
import torch.nn.functional as Fdef rectified_linear2(m,b,x): return F.relu(m*x+b)
plot_function(partial(rectified_linear2, 1,1))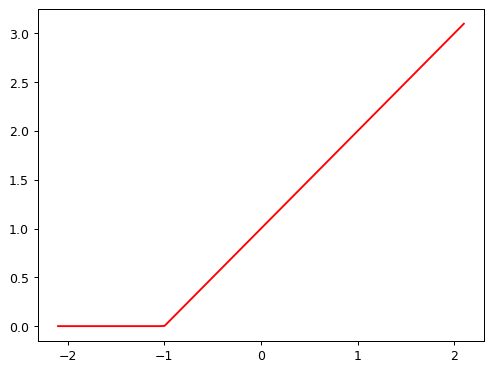
To understand how this function works, try using this interactive version to play around with the parameters m and b:
@interact(m=1.5, b=1.5)
def plot_relu(m, b):
plot_function(partial(rectified_linear, m,b), ylim=(-1,4))As you see, m changes the slope, and b changes where the “hook” appears. This function doesn’t do much on its own, but look what happens when we add two of them together:
def double_relu(m1,b1,m2,b2,x):
return rectified_linear(m1,b1,x) + rectified_linear(m2,b2,x)
@interact(m1=-1.5, b1=-1.5, m2=1.5, b2=1.5)
def plot_double_relu(m1, b1, m2, b2):
plot_function(partial(double_relu, m1,b1,m2,b2), ylim=(-1,6))If you play around with that for a while, you notice something quite profound: with enough of these rectified linear functions added together, you could approximate any function with a single input, to whatever accuracy you like! Any time the function doesn’t quite match, you can just add a few more additions to the mix to make it a bit closer. As an experiment, perhaps you’d like to try creating your own plot_triple_relu interactive function, and maybe even include the scatter plot of our data from before, to see how close you can get?
This exact same approach can be expanded to functions of 2, 3, or more parameters.
OK great, we’ve created a nifty little example showing that we can drawing squiggly lines that go through some points. So what?
Well… the truth is that actually drawing squiggly lines (or planes, or high-dimensional hyperplanes…) through some points is literally all that deep learning does! If your data points are, say, the RGB values of pixels in photos of owls, then you can create an owl-recogniser model by following the exact steps above.
This may, at first, sound about as useful as the classic “how to draw an owl” guide:
Students often ask me at this point “OK Jeremy, but how do neural nets actually work”. But at a foundational level, there is no “step 2”. We’re done – the above steps will, given enough time and enough data, create (for example) an owl recogniser, if you feed in enough owls (and non-owls).
The devil, I guess, is in the “given enough time and enough data” part of the above sentence. There’s a lot of tweaks we can make to reduce both of these things. For instance, instead of running our calculations on a normal CPU, as we’ve done above, we could do thousands of them simultaneously by taking advantage of a GPU. We could greatly reduce the amount of computation and data needed by using a convolution instead of a matrix multiplication, which basically means skipping over a bunch of the multiplications and additions for bits that you’d guess won’t be important. We could make things much faster if, instead of starting with random parameters, we start with parameters of someone else’s model that does something similar to what we want (this is called transfer learning).
And, of course, there’s lots of helpful software out there to do this stuff for you without too much fuss. Like, say, fastai.
Learning these things is what we teach in our course, which, like everything we make, is totally free. So if you’re interested in learning more, do check it out!
As always, if you enjoyed this notebook, please upvote it to help others find it, and to encourage me to write more. If you upvote it, be careful you don’t accidentally upvote your copy that’s created when you click “Copy & Edit” – you can find my original at this link.